
徐振中 28 分钟阅读
我的名字是徐振中, 我于2015年加入Netflix,担任实时数据基础设施团队的创始工程师,后来领导了流处理引擎团队。我在2010年代初就对实时数据产生了兴趣,并从那时起就认为有很多价值有待发掘。
Netflix是一个奇妙的地方,被许多了不起的同事所包围。我为参与这个将共同信念变为现实的旅程的每个人感到无比自豪。我想用简短的时间来分享团队的主要成就。
- 我们把Netflix所有组织的流数据使用案例从0增加到2000多个。
- 我们建立并发展了成功的产品,如 Keystone, managed Flink Platform, Mantis和管理的Kafka平台。这些产品在数据生态系统的许多方面提供解决方案:包括数据摄取、移动、分析和操作处理以及机器学习用例。
- 我们是行业内第一批扩大开源Kafka和Flink部署的公司,在2017年左右每天处理1万亿个事件,后来到2021年又扩大了20倍的规模
几个月前,我离开了Netflix,去追求一个类似但更大的愿景。 实时机器学习,我认为现在是总结我在Netflix建立实时数据基础设施的经验的最佳时机。我希望这篇文章能帮助平台工程师开发他们的云原生、自助服务的流数据平台,并在许多业务功能中扩展用例(不一定是来自我们的成功,可能更多的是来自我们的失败)。我也相信,了解数据平台的构建方式可以帮助平台用户(如数据科学家和ML工程师)充分利用他们的平台。
我将分享实时数据基础设施在Netflix的四个阶段的迭代历程(2015-2021)。
Phase 1: 从批处理管道中拯救Netflix的日志数据(2015)
在Netflix的全球超增长期间,业务和运营决策比以往任何时候都更依赖于更快的记录数据。在2015年,基于Chukwa/Hadoop/Hive的批处理管道难以扩展。在这个阶段,我们从头开始建立了一个流数据优先的平台,以取代失效的管道。
Phase 2: 扩展100个数据移动的使用案例 (2016)
在最初的产品发布后,内部对数据移动的需求稳步上升。我们不得不把重点放在常见的用例上。在这个阶段,我们通过建立一个具有简单而强大的构件设计的自我服务、完全管理的平台,扩展到支持100多个用例。
Phase 3: 支持客户需求,扩展到1000个用户案例(2017–2019)
随着流处理在Netflix的发展势头,许多团队要求在数据工程、可观察性和机器学习领域有更低的延迟和更多的处理灵活性。在这个阶段,我们建立了一个新的流处理开发经验,以实现定制的用例,我们还解决了新的工程和运营挑战。
Phase 4: 扩展流处理的责任,挑战和机会并存 (2020 — Present)
随着行业内数据平台技术的快速发展,出现了很多新的挑战:协调困难、学习曲线陡峭、流与批的界限分化等。在这个阶段,我们探讨了流处理在连接技术和提高抽象性方面发挥了更突出的作用,使数据平台更容易使用。摆在我们面前的机会还有很多。
对于每个阶段,我都会去了解不断变化的商业动机、团队的独特挑战、战略赌注,以及我们一路走来发现的用例模式。
许多人帮助我审查这个帖子,如果没有他们的反馈,我永远不会挖掘出许多不偏不倚的细节。特别感谢 Chip Huyen, Steven Wu, Prashanth Ramdas, Guanhua Jiang, Scott Shi, Goku Mohandas, David Sun, Astasia Myers, , 和 Matt Willian!
Netflix的实时数据基础设施的四个阶段
第一阶段:从失败的批处理管道中拯救Netflix日志(2015年)。
背景介绍
2015年,Netflix已经拥有约60MM的用户,并且正在积极地扩展其国际业务。我们都知道,迅速扩大平台的杠杆作用将是维持用户飞速增长的关键。
题外话:对于那些不熟悉的人来说,平台团队通过集中管理基本的基础设施来提供优势,这样产品团队就可以专注于业务逻辑。
我们的团队必须弄清楚如何帮助Netflix扩展日志实践。当时,Netflix有~500个微服务,每天在生态系统中产生超过10PB的数据。
收集这些数据对Netflix来说有两个主要目的。
- 获得商业分析洞察力(例如,用户保留率、平均会话长度、什么是趋势等)。
- 获得运营洞察力(例如,测量 streaming plays per second来快速、轻松地了解Netflix系统的健康状况),因此开发人员可以发出警报或执行缓解措施。
你可能会问,为什么我们首先需要将日志从边缘转移到数据仓库?由于数量庞大,在在线交易数据库上大规模地进行按需分析是不可行的。原因是,在线交易处理(OLTP)和在线分析处理(OLAP)是以不同的假设建立的--OLTP是为面向行的访问模式建立的,而OLAP是为面向列的访问模式建立的。在引擎盖下面,它们使用不同的数据结构进行优化。
例如,假设我们想知道数以亿计的Netflix用户的平均会话长度。假设我们把这个按需分析的查询放在一个面向行的OLTP系统上。它将导致行级粒度的全表扫描,并有可能锁定数据库,应用程序可能变得没有反应,导致不愉快的用户体验。这种类型的分析/报告工作负载最好在OLAP系统中完成,因此需要以低延迟的方式可靠地移动日志。
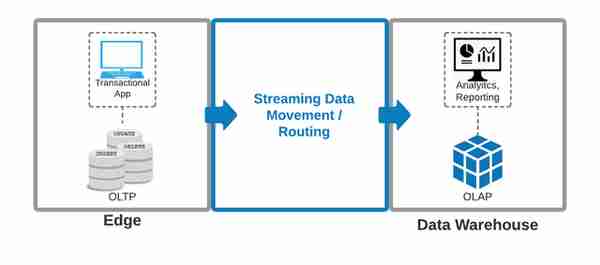
(图:将数据从边缘地带移到数据仓库)
到2015年,日志量已经从2011年的450亿事件/天增加到5000亿事件/天(1PB的数据摄取)。现有的日志基础设施(一个用Chukwa、Hadoop和Hive构建的简单的批处理管道平台)在每周惊人的用户数量增加的情况下迅速失效。据估计,我们有大约6个月的时间来演变为一个流数据优先的解决方案。下图显示了从失败的批处理架构到新的基于流的架构的演变过程。
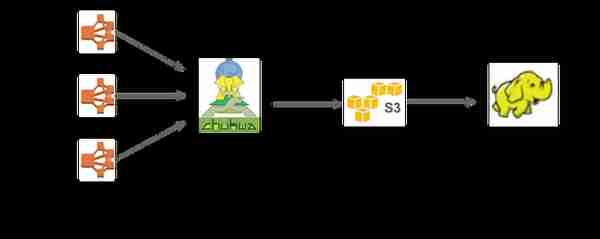
(图:迁移前失败的批处理管道架构)。
我们决定用以下方式取代这个失败的基础设施 Keystone.
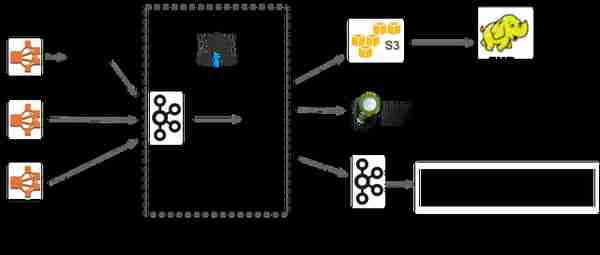
(图:迁移后的Keystone流媒体架构)
你可能有的另一个问题是,为什么要考虑采用流处理优先架构?当时,搞好流处理架构的价值超过了潜在的风险。Netflix是一家数据驱动的公司,流处理架构的直接重要性在于。
- 减少开发者和运营的反馈循环。开发人员在很大程度上依靠查看日志来做出运营决策。访问更新鲜的按需日志,使开发人员能够更早发现问题,从而提高生产力。
- 更好的产品体验。许多产品功能,如个性化推荐、搜索等,都可以从更新鲜的数据中获益,以改善用户体验,从而提高用户保留率和参与度等。
挑战
在建立流平台的过程中,我们必须考虑到许多挑战。
挑战1。规模大,资源有限。我们有六个月的时间来建立Keystone,每天处理500B的事件,我们必须用六个团队成员来完成这个任务。
挑战2:不成熟的流生态系统。在2015年,当传输(Apache Kafka)和处理技术(Apache Samza、Apache Flink)都相对新兴的时候,开发和运营流优先的基础设施是很困难的。很少有技术公司在我们所需要的规模上证明了成功的流优先部署,所以我们不得不评估技术选择和实验。鉴于我们的资源有限,我们不可能自己建立所有的东西,我们必须决定建立什么,以及押注哪些新生的工具。
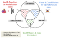
挑战3:分析性和操作性的关注点不同。
- 分析性流处理的重点是正确性和可预测性。例如,将所有的用户点击流转移到数据仓库,需要数据的一致性(最小的重复或损失)和对通常在几分钟范围内的延迟的可预测性。(Keystone在这方面做得很好)
- 业务流处理更注重成本效益、延迟和可用性。例如,了解整个Netflix设备生态系统的健康状态可以从亚秒级到秒级的延迟中受益,而且数据可以从源头采样或剖析以节省成本。(Mantis在这方面很擅长)
挑战4:有状态数据平台的云原生弹性很难。Netflix已经在AWS云上运行了几年。然而,我们是第一个将有状态的数据平台放到容器化云基础设施上的人。每个数据中心都有几十万台物理机器在为云计算提供动力,在引擎盖下。在这种规模下,硬件故障是不可避免的。当这些故障意外出现时,系统要跟上可用性和一致性的预期,可能是一个挑战。在一个无界的低延迟流处理环境中,任何故障恢复都会导致背压的积累,这就更具有挑战性了。流优先架构的云原生复原力将意味着重大的工程挑战。
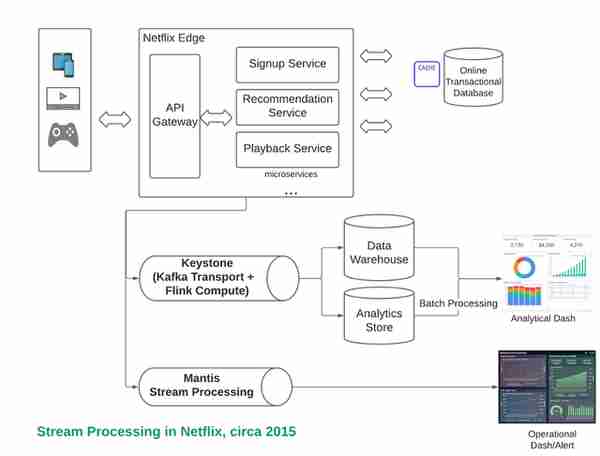
(图。流处理是如何帮助操作和分析数据的)
策略赌注
赌注1:在建立MVP产品时,要为最初的几个客户建立它。在探索最初的产品-市场契合度时,很容易被分散注意力。我们决定只帮助几个高优先级、高数量的内部客户,以后再担心扩大客户群的问题。这个决定不仅使我们能够专注于产品的核心。它还使我们意识到什么是不应该投资的(例如,我们用电子表格而不是一个成熟的控制平面来保存客户的名字、电子邮件地址和每个管道的元数据信息,以方便在MVP阶段的客户部署)。
赌注2:与技术伙伴共同发展,即使不处于理想的成熟状态,而不是自己重新发明车轮。这样一来,我们就可以共同发展生态系统了。我们在早期就选择了合作。
- 流媒体合作伙伴。在外部,我们与那些引领行业流处理工作的合作伙伴合作,例如LinkedIn(Kafka和Samza团队)、Confluent、Data Artisan(Apache Flink背后的建设者,后来改名为Veverica)。这样做 使我们能够为我们的需求贡献开放源码软件,同时利用社区的工作。
- 容器化合作伙伴:在2015年,这还是容器虚拟化技术的早期阶段。我们需要一个战略来快速部署。在 内部,我们与新创建的容器基础设施建立了伙伴关系 Titus team.Titus建立在Apache Mesos之上,通过抽象的API,提供计算资源管理、调度和隔离部署。Titus后来在2020年初发展到利用K8S,他们的团队设法透明地迁移所有工作负载。由于这种合作关系,我们在建立数据平台时不必担心底层的计算基础设施。
在合作过程中,我们一直保持沟通,分享学习成果并提供反馈。我们每两周与亲密的合作伙伴举行一次同步会议,以统一目标并讨论问题和解决方案。当出现阻碍性问题时,合适的人将会立即参与进来。
赌注3:将关注点脱钩,而不是忽略它们。
- 将运营和分析用例之间的问题分开。我们将Mantis(以运营为重点)和Keystone(以分析为重点)分开发展,但为这两个系统创造了接口空间。
(图:不同流处理方案的关注点分离)
- 分离生产者和消费者之间的关注。我们引入了生产者/消费者客户端,配备了标准化的电线协议和简单的模式管理,以帮助生产者和消费者的开发工作流程脱钩。它后来被证明是数据治理和数据质量控制的一个重要方面。
- 分离的组件责任。我们从面向微服务的单一责任原则开始,将整个基础设施分为消息(流传输)、处理(流处理)和控制平面(控制平面在这个阶段只是一个脚本,后来演变成一个成熟的系统)。组件责任的分离使团队在早期就能在接口上保持一致,同时通过同时关注不同的部分来 释放团队的生产力。
赌注4:投资建立一个预期会发生故障并监控所有操作的系统,而不是拖延投资。由于云的弹性、不断变化、故障概率较高的特点,我们需要设计系统来监测、检测和容忍各种故障。故障的范围包括网络突发事件、实例故障、区域故障、集群故障、服务间拥堵和背压、区域灾难故障等。我们在构建系统时,假设故障是持续的。我们在早期就接受了DevOps实践:如针对故障场景的设计、严格的自动化、持续部署、影子测试、自动化监控、警报等。这种DevOps的基础使我们拥有最终的工程敏捷性,可以每天多次发货。

(参考。 What is Chaos Money in DevOps在Quora上)
经验之谈
拥有一个心理上安全的失败环境,对任何团队领导变革都是至关重要的。
我们犯了很多错误。我们在产品发布当天惨遭失败,并发生了一次全公司范围内的事故,造成了大量的数据丢失。经过调查,发现尽管我们正确估计了流量的增长,但我们建立的巨大的Kafka集群(有超过200个Broker)太大,最终达到了它的扩展极限。当一个Broker死亡时,由于Kafka(当时)对Broker和分区数量的限制,该集群无法自行恢复。它最终退化到了无法恢复的地步。
在这种规模下失败是一种可怕的经历,但由于心理上安全的团队环境,我们与所有利益相关者进行了透明的沟通,并将快速的学习成果转化为永久性的解决方案。对于这个特殊的案例,我们开发了更细化的集群隔离能力(更小的Kafka集群+隔离的Zookeeper)来控制爆炸半径。
还有许多其他故障。当我们挖掘根源时,我们意识到我们无法完全预测所有的边缘情况,特别是当我们在管理云上构建时,变化往往不在我们的控制范围内,如实例终止或租户主机托管等。同时,我们的产品被很多人使用,太重要了,不能失败。同时,我们的产品被很多人使用,太重要了,不能失败。这成为了一个操作原则,总是为最坏的情况做准备。
事件发生后,我们采用了每周一次的Kafka集群故障切换演练。每周值班人员都会模拟一个Kafka集群故障。团队将确保故障转移自动化工作,以最小的用户影响将所有流量迁移到一个健康的集群。如果你有兴趣了解更多关于这一做法的信息,请看 video有更多的细节。
第二阶段:规模化的100个数据移动用例(2016)。
背景介绍
在运送了最初的Keystone MVP和迁移了一些内部客户后,我们逐渐获得了一些信任,话语也传到了其他工程团队。流媒体在Netflix获得了发展势头,因为现在很容易移动日志进行分析处理,并获得按需的运营洞察力。
现在是我们为普通客户扩大规模的时候了。
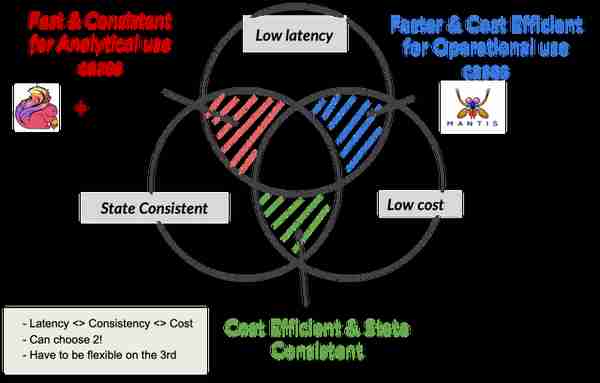
(图:不断发展的Keystone架构图,约2016年。Keystone包括Kafka和Flink引擎作为其核心组件。关于更多的技术设计细节,请参考博文,主要是关于 Kafka和 Flink)
挑战
挑战1:运营负担增加。我们最初为新客户的入职提供白手套协助。然而,考虑到不断增长的需求,这很快变得不可持续。我们需要开始发展MVP,以支持超过十几位客户。因此,我们需要重建一些组件(例如,是时候把电子表格变成一个适当的数据库支持的控制平面了)。
挑战2:出现多样化的需求。随着我们得到更多的客户要求,我们开始看到非常多样化的需求。有两个主要类别。
- 一组人倾向于使用简单的,完全管理的服务。
- 另一组人更喜欢灵活性,需要复杂的计算能力来解决更高级的业务问题,他们可以接受传呼,甚至管理一些基础设施。
我们不可能同时做好这两件事。
挑战3:我们打破了我们所接触的一切。不开玩笑,由于规模太大,我们几乎在某些时候破坏了所有的依赖服务。我们破坏了S3。我们在Kafka和Flink中发现了许多bug。我们破坏了 Titus(管理容器基础设施)多次,并发现了奇怪的CPU隔离和网络问题。我们打破了 Spinnaker(持续部署平台),因为我们开始以编程方式管理数百个客户的部署。
幸运的是,这些团队也是最好的。他们与我们合作,逐一解决这些问题。这些努力对于整个流媒体生态系统的成熟至关重要。
策略赌注
赌注1:首先关注简单性,而不是将基础设施的复杂性暴露给用户。我们决定首先关注高度抽象的、完全管理的服务,用于一般的流媒体使用案例,原因有二。
- 这将使我们能够解决大多数数据移动和简单的流式ETL(例如,投影、过滤)用例。为数据路由提供这种简单、高层次的抽象,将使所有Netflix组织的工程师能够将数据路由作为一个 "乐高 "积木,与其他平台服务一起使用。
- 这将使我们的用户能够专注于业务逻辑。
我们将在以后处理更高级的用例。
赌注2:投资于完全管理的多租户自助服务,而不是继续使用手动的白手套支持。我们必须专注于控制平面和工作负载部署的自动化。客户的工作负载需要完全隔离。我们决定,一个客户的工作负载不应该以任何方式干扰另一个客户的工作负载。
(图。显示了一个由完全管理的多用户流媒体基础设施提供的自助式拖放体验)。
赌注3:继续投资于DevOps,而不是拖延它。我们希望根据需要每天多次运送平台变化。我们也相信有必要让我们的客户能够随时运送变化。部署应该在客户启动后几分钟内自动完成并安全地滚入生产。
经验之谈
学习1:决定不做什么是困难的,但却是必要的。虽然解决客户的要求很重要,但有些要求可能会让人分心。确定优先次序是第一步,但有意识地决定和沟通要削减的内容更为关键。说 "不 "是困难的。但要注意说 "不 "是暂时的,而说 "是 "是永久的。
学习2:注意扩展速度。在最初的产品-市场契合度得到验证后,这是一个令人兴奋的时期。然而,扩展速度太快会使团队有可能从多个方向分心,留下大量的技术债务,并破坏客户的信任。扩张得太慢会使团队失去动力,客户需求长期得不到满足,也会破坏他们的信任。这是一个微妙的平衡,但这里有一些你可以注意的信号。
- 软件质量。部署回滚的频率是否有变化?合作伙伴团队多久会阻挠一次?现在测试失败的频率高吗?由于任何系统瓶颈而发生事故的频率如何?
- 客户的情绪。客户支持请求的增加是否与用例的数量呈亚线性关系?违反SLO的趋势。客户在新功能公告中是否表现出兴奋?当有客户的 "紧急 "要求时,他们考虑过哪些替代方案?
- 运营开销。团队的运营与开发时间的比率是否改变?RCA与事故的比率是否改变?团队是否因运营劳累而疲惫不堪?团队的创新频率是否发生变化(例如,博客文章、会议讲座)?
学习3:教育你的用户,并耐心地纠正错误观念。在数据质量方面有很多流处理的误区,比如事件损失或重复,或者处理语义方面的误区,比如失败情况下的正确性保证。这些误解中有很多来自于流处理不成熟的旧时代,但现在已经有了很大的发展。对你的用户要有耐心,用数据和故事来教育他们。
第三阶段:支持定制需求和超越1000个用例的规模(2017-2019年)
背景介绍
在最初推出Keystone产品的一年后,所有组织的用例数量迅速从2015年的不到十几个上升到2017年的几百个。此时,我们已经建立了一个坚实的运营基础:客户的oncalls期间很少被通知,所有的基础设施问题都由平台团队密切监控和处理。我们已经建立了一个强大的交付平台,帮助我们的客户在提出意图后几分钟就能将变化引入生产。
Keystone产品在其最初设计的功能方面非常出色:一个易于使用且几乎可以无限扩展的流数据路由平台。然而,越来越明显的是,流处理的全部潜力还远远没有实现。为了满足定制的用例,我们不断发现对复杂处理能力的更精细控制的新需求,如流式连接、窗口化等。
同时,Netflix有一个独特的自由和责任文化,每个团队都被授权做出自己的技术决定。这种文化使每个团队甚至可以投资于定制的解决方案。作为一个中央平台团队,我们注意到这样的增长。如果我们没有办法提供保障,就意味着公司的长期成本很高。
现在是该团队扩大范围的时候了。我们再次面临一些新的挑战。
挑战
挑战1:自定义用例需要不同的开发人员和操作经验。
让我先举两个自定义流处理的用例。
- 计算 streaming ground truth for Recommendation.为了让Netflix推荐算法提供最佳体验,有必要用最新的数据来训练模型。训练模型的输入之一是标签数据集。标签是以前的个性化预测是否准确的直接地面真实指标。如果用户决定看一部电影的推荐,我们就有一个正面的标签。你可以猜到,我们越快得到这个标签数据集,整个ML反馈循环就越快。为了计算标签,我们需要把印象流和用户点击流连接起来。然而,用户的点击活动往往会迟到。例如,用户有时会花几分钟时间来决定,或者干脆让他们的设备开着不看几个小时。该用例要求流媒体管道在所有相关信息到达时立即发出标签,但仍能容忍晚到的信息。
- 计算 take-fraction for Recommendation. Netflix进行个性化推荐以优化用户体验。其中之一是选择最佳个性化艺术品(以及展示它们的最佳位置)的算法,以优化用户的收视率。在引擎盖下,一个流处理管道通过在一些自定义窗口上将播放数据流与印象流连接起来,以近乎实时的方式计算出这个取分指标。由于Netflix数以亿计的用户规模,流媒体工作需要不断检查1-10TB之间的内部状态。

通过A/B测试,选择最佳的艺术品来为用户提供个性化服务 Selecting the best artwork for videos through A/B testing
这些用例涉及更高级的流处理能力,如复杂的事件/处理时间和窗口语义,允许的延迟,大状态检查点管理。它们还需要围绕可观察性、故障排除和恢复的更多操作支持。一个全新的开发者体验是必要的,包括更灵活的编程接口和操作能力,如自定义可观察性堆栈、回填能力,以及管理10多个TB本地状态的适当的基础设施。我们在Keystone中没有这些,我们需要建立一个新的产品入口,但要尽量减少冗余的投资。
挑战2:在灵活性和简单性之间取得平衡。随着所有新的定制用例的出现,我们必须弄清楚适当的控制暴露水平。我们可以完全暴露最低级别的API,但同时也要牺牲更多具有挑战性的操作(因为我们永远无法完全预测用户将如何使用该引擎)。或者我们可以选择走中间路线(例如,暴露有限的功能),冒着让客户不满意的风险。
挑战3:增加操作的复杂性。支持自定义用例要求我们增加平台的自由度。因此,我们需要改善许多复杂场景下的操作可观察性。同时,随着平台与许多其他数据产品的整合,我们系统的接触点增加,需要与其他团队进行业务协调,以更好地服务我们的集体客户。
挑战4:中央平台与本地平台。我们团队的责任是提供一个集中的流处理平台。但是由于之前的策略是专注于简单性,一些团队已经在他们的本地流处理平台上投资,使用不支持的技术,例如Spark Streaming。我们必须说服他们重新回到铺设好的道路上,因为他们有可能失去平台的杠杆作用,并在多余的投资上浪费资源。现在是合适的时机,因为我们扩展到了自定义用例。
策略赌注
赌注1:建立一个新的产品入口,但重构现有架构,而不是孤立地建立一个新产品。在分析处理方面,我们决定从原来的架构中剥离出一个新的平台,以暴露出Apache Flink的流处理的全部能力。我们将从头开始创建一个新的内部客户群,但我们也决定现在是重构架构的正确时机,以尽量减少冗余投资(在Keystone和Flink平台之间)。在这个新架构中,较低的Flink平台同时支持Keystone和自定义用例。
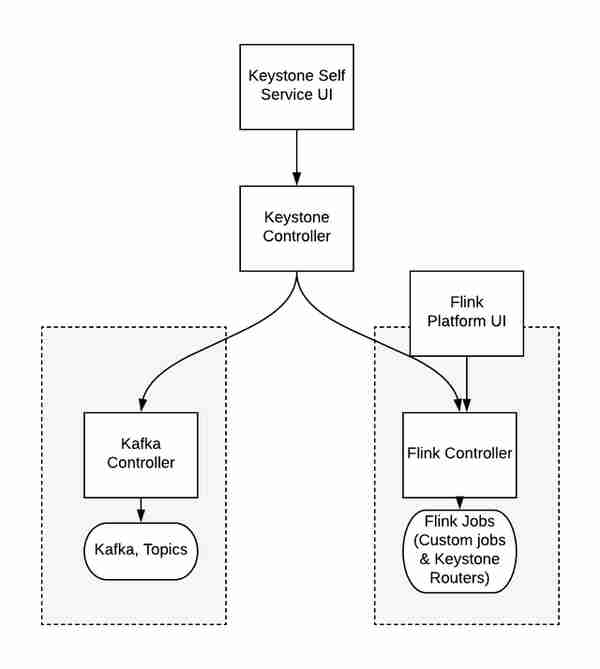
(图。架构将Flink平台分割为一个独立的产品入口点)
赌注2:从流式ETL和可观察性用例开始,而不是一下子解决所有的自定义用例。有很多机会,但我们决定把重点放在分析方面的流式ETL用例和操作方面的实时观察用例上。由于其复杂性和规模,这些用例是最具挑战性的。为了充分展示流处理的力量,我们首先解决最困难的用例并从中学习是有意义的。
赌注3:最初与客户分担运营责任,并逐渐共同创新,随着时间的推移降低负担。我们非常幸运,我们的早期采用者都是自给自足的,只要客户有困难,我们还提供白手套的支持模式。我们逐渐扩大运营投资,如自动缩放、管理部署、智能警报、回填解决方案等。
经验之谈
学习1:支持新的自定义用例的新产品入口是一个必要的进化步骤。这也是一个重新架构/重构并融入现有产品生态系统的机会。不要被引诱去构建一个孤立的新系统。避免 second-system effect.
学习2:简单性吸引了80%的用例。灵活性有助于更大的用例。回顾一下,这些是对过去几年实际客户群的观察。我想在这里向读者传达的观点是,在支持大多数用例或影响较大的用例之间确定优先次序,完全取决于情况。争论可以用两种方式进行,但你应该阐明符合你的业务方案的理由。
简单性和灵活性不是光谱的两端。这是一个封闭的创新反馈回路。灵活性的力量将推动与一小部分客户进行新的共同创新。在开始时,这些创新可能更昂贵,但在它被证明后,价值最终可能成为一种商品,回到简化的经验。当这些新价值帮助成长中的客户时,一小部分新用户会再次要求获得灵活性的力量。
学习3:善待你的早期采用者。他们是最忠诚的客户,会免费为你做营销。由于早期采用者的认可,我们的使用案例在这个阶段爆炸性地增加到数千。
学习4:当东西损坏时,不要惊慌。相信你周围所有的人。如果你已经有一个支持产品的社区,那就加分。我记得有一段时间,我们经历了整个平台的缓慢退化。每天,我们都会收到大量的页面,而我们在两个星期内都无法找出根本原因。这很可怕,团队很痛苦,客户也很痛苦。但是,团队能够跨越团队的界限,让具有正确专业知识的人参与进来,利用数据对症状进行逻辑推理,共同工作。最终,我们发现了Linux内核中的一个错误,它导致了流媒体工作负载的缓慢内存泄漏。我们必须信任所有参与其中的人,有时甚至在我们不具备所有专业知识的情况下也是如此。
第四阶段:扩大流处理的责任--未来的挑战和机遇(2020年-现在)
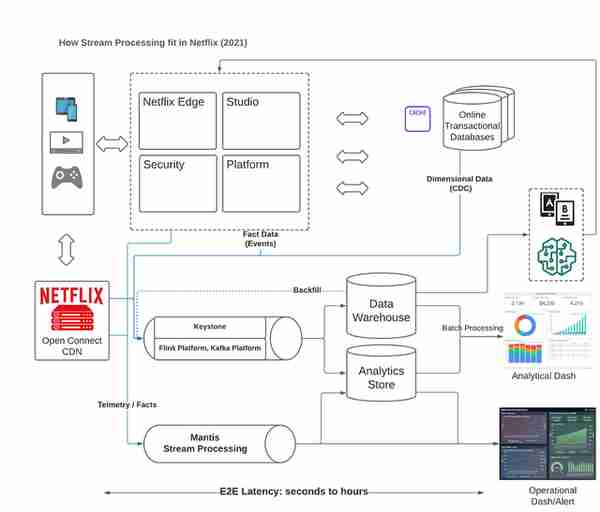
(图:流处理如何适合Netflix - 2021年)
背景介绍
随着流处理的使用案例扩展到Netflix的所有组织,我们发现了新的模式,并且我们享受了早期的成功。但现在还不是自满的时候。
Netflix作为一个企业,继续探索新的领域,并在内容制作室和最近的游戏领域进行了大量投资。一系列新的挑战出现了,我们跳进了解决这些有趣的问题空间。
挑战
挑战1。不同的数据技术使协调变得困难。由于团队被授权,Netflix的许多团队都在使用各种数据技术。例如,在事务性方面:有Cassandra、MySQL、Postgres、CockroachDB、Distributed Cache等。在分析方面:有Hive, Iceberg, Presto, Spark, Pig, Druid, Elasticsearch等。在Netflix的数据生态系统中,同一数据的许多副本往往被存储在不同的数据存储中。
由于有许多选择,把技术放在划分的桶里是人类的天性。批量与流。事务性存储与分析性存储。在线处理与离线处理。这些都是数据世界中经常争论的话题。重叠的分界线往往给终端用户带来更多的困惑。
今天,跨技术边界的数据协调和工作是令人难以置信的挑战。前沿是很难用划分的边界来推动的。
挑战2:更陡峭的学习曲线。随着可用数据工具的不断增加和专业化程度的持续加深,用户要学习并决定什么技术适合特定的使用情况,这对他们来说是一个挑战。
挑战3:ML实践没有利用数据平台的全部力量。之前提到的所有挑战都给ML实践带来了损失。数据科学家的反馈回路很长,数据工程师的生产力受到影响,产品工程师在分享有价值的数据方面遇到挑战。最终,许多企业失去了适应快速变化的市场的机会。
挑战4:中央平台模式的规模限制。随着中央数据平台以超线性的速度扩展用例,单点支持的做法是不可持续的。现在是评估中央平台支持地方-中央平台以增加杠杆的模式的时候了(这意味着我们将优先支持建立在我们平台之上的地方平台)。
机会
我将对这部分内容进行相对简单的介绍,并在今后的博文中展开详细介绍。
用流来连接世界。对于流处理,除了低延迟处理的优势外,它在现代数据平台中越来越显示出更关键的优势:连接各种技术,实现流畅的数据交换。诸如变化数据捕获(CDC)、流式物化视图和数据网格概念等技术正在得到普及。最后,马丁-克莱普曼在2015年提出的""愿景开始实现其价值。Turning Database Inside Out”开始实现其价值。
通过结合简单性和灵活性的优点来提高抽象性。了解各种数据技术的深层内部结构有很多价值,但不是每个人都需要这样做。在云优先的数据基础设施正在成为商品的时候,这种思路尤其正确。适当提高数据基础设施的抽象性,成为让更多人容易获得所有先进能力的直接机会。诸如流式SQL等技术将降低入门门槛,但这只是个开始。数据平台也应该提高抽象度,使最终用户看不到分界线(例如,流媒体与批处理)。
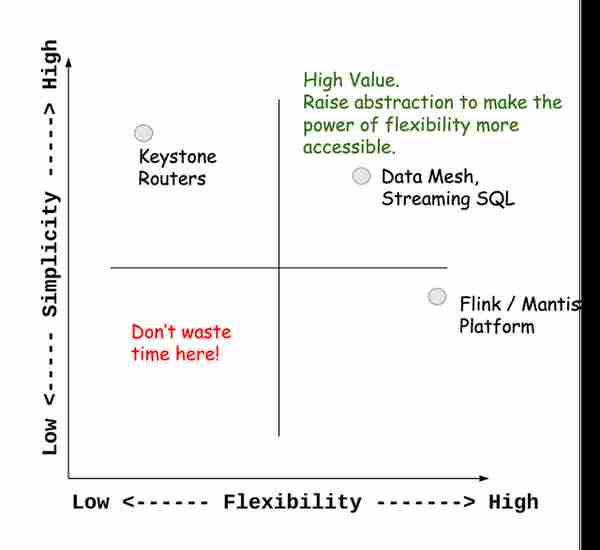
(图:简单性和灵活性之间的甜蜜点)
机器学习需要现代数据平台的更多关爱。可以说,ML人是对商业影响最大的,也是所有开发者角色中服务最差的群体。所有的ML平台都依赖于数据存储和处理。因此,数据平台有很多机会向ML世界伸出援助之手:如数据质量、可靠性和可扩展性、开发到生产的反馈回路、实时观察能力、整体效率等。
下一个前沿领域是什么
谢谢你走到这一步。这篇博文描述了在Netflix建立流处理基础设施的高层次迭代历程。我希望听到你对有趣的事情的反馈,这样我就可以在以后的博文中跟进。
根据设计,我在这篇文章中省略了许多技术细节。但如果你有兴趣了解更多,请参考附录部分,了解Netflix所有流处理创新的完整时间线。
我对数据基础设施的未来感到非常兴奋,特别是为了支持更好的机器学习体验。我相信这是我们应大胆走向的下一个前沿领域!"。如果你有兴趣,我强烈建议你阅读""。Real-time machine learning: challenges and solutions"我的朋友和同事奇普(Chip)的文章。
我也很高兴地宣布,我将开始一个新的旅程,在 Chip Huyen开始了新的旅程,致力于开发一个流媒体优先的机器学习平台。我们仍处于早期阶段,我们正在寻找一位 founding infrastructure engineer来共同塑造未来!如果你对我们感兴趣,我们很愿意为你提供帮助。
如果这篇博文与你产生共鸣,请联系我们。我愿意与你联系!
参考文献
按时间顺序排列的索引...
- [2015|用例] What’s trending on Netflix? improving our recommender systems
- [2015|用例] SPS: the Pulse of Netflix Streaming | by Netflix
- [2016|平台] Evolution of the Netflix Data Pipeline | by Netflix
- [|2016Platform] Kafka Inside Keystone Pipeline
- [2016|平台] Stream-processing with Mantis… | by Netflix
- [2017|平台] Running a Massively Parallel Self serve Distributed Data System At Scale — Zhenzhong Xu
- [2017|平台] FlinkForward: Stream Processing with Flink at Netflix — Monal Daxini
- [2017|平台] Custom, Complex Windows at Scale using Apache Flink — Matt Zimmer (Netflix)
- [2017|用例] Streaming for Personalization Datasets at Netflix
- [2017|用例] ChAP: Chaos Automation Platform | by Netflix
- [2018|平台] Keystone Real-time Stream Processing Platform | by Netflix
- [2018|用例] “Scalable Anomaly Detection (with Zero Machine Learning)” by Arthur Gonigberg
- [2018|用例] Migrating Batch ETL to Stream Processing: A Netflix Case Study with Kafka and Flink
- [2018|Platform] Building Stream Processing as a Service (SPaaS) — Steven Wu
- [2018|平台] Cloud-Native and Scalable Kafka Architecture
- [|2019Platform] Scaling Flink in Cloud — Steven Wu
- [2019|用例] Massive Scale Data Processing at Netflix using Flink — Snehal Nagmote & Pallavi Phadnis
- [2019|用例] Cost-Effective, Realtime Operational Insights Into Production Systems
- [2019|用例] Real-time Processing with Flink for Machine Learning at Netflix — Elliot Chow
- [2019|平台] Open Sourcing Mantis: A Platform For Building Cost-Effective, Realtime, Operations-Focused Applications | by Netflix
- [2019|平台] Netflix Data Mesh: Composable Data Processing — Justin Cunningham
- [|2019Platform] Netflix: Evolving Keystone to an Open Collaborative Real-time ETL Platform — Alibaba Cloud Community
- [2019|用例] Delta: A Data Synchronization and Enrichment Platform | by Netflix
- [2019|用例] DBLog: A Generic Change-Data-Capture Framework | by Netflix
- [|2020Platform] Autoscaling Flink at Netflix — Timothy Farkas
- [2020|用例] How Netflix Uses Kafka for Distributed Streaming — by Confluent
- [2020|用例] Building metric platform using Flink for massive scale at Netflix — Abhay Amin
- [2020|用例] Taming Large State: Lessons from Building Stream Processing Joins for Datasets for Personalization
- [2020|用例] Building Netflix’s Distributed Tracing Infrastructure | by Netflix
- [2020|用例] Telltale: Netflix Application Monitoring Simplified | by Netflix
- [2020|使用案例] [|使用案例 How Netflix uses Druid for Real-time Insights to Ensure a High-Quality Experience
- [2021|平台] Data Movement in Netflix Studio via Data Mesh | by Netflix
- [|2021Platform] Backfill Flink Data Pipelines with Iceberg Connector
- [|2022Platform] Auto-Diagnosis and Remediation in Netflix Data Platform | by Netflix